#! https://zhuanlan.zhihu.com/p/689591662
深入理解LLVM的Value、User、Use
https://laity000-learning-notes.readthedocs.io/en/latest/llvm/llvm_value.html
↑推荐上面原文阅读↑
一句话:llvm源码中通过value、user、use这些基础类来表示llvm ir和他们之间的def-use关系(或者说user-usee)。
预备知识点
什么是llvm ir?:首先需要了解llvm ir的基础概念和设计,可以直接看官方介绍llvm ir的视频,我也写了一篇笔记
为什么llvm ir需要ssa?:llvm ir中除了alloca/store/load都是SSA形式的,在创建SSA形式的llvm ir时,SSA value之间的def-use信息也会一同被建立。具体解析可以看下面文章:
相关文章
下面是已有的优秀文章:
本文是对上述文章的总结和补充,用来加深理解,如有不对之处请指正。
源码llvm17.0.6
概要
llvm::Value既可以是User,也可以是UseeUser–>Usee关系: 一条Instruction(Value)通过User创建固定数量个Use,这里Use类可以理解成槽的概念,用来放置被使用的Value
Usee–>User关系:槽之间可以链接,代表Usee–>User关系。具体来说,一个value可以放到多个use中,放置/替换value到use槽里的同时,会将use链接到这个新的value的uselist链表上(通过头插法+双重指针来维护uselist链表),这样整个Value–>User关系就维护起来了
所以use和value是包含关系,而User继承自Value
一切皆value
我们看下llvm::value的定义:
/// LLVM Value Representation
///
/// This is a very important LLVM class. It is the base class of all values
/// computed by a program that may be used as operands to other values. Value is
/// the super class of other important classes such as Instruction and Function.
/// All Values have a Type. Type is not a subclass of Value. Some values can
/// have a name and they belong to some Module. Setting the name on the Value
/// automatically updates the module's symbol table.
///
/// Every value has a "use list" that keeps track of which other Values are
/// using this Value. A Value can also have an arbitrary number of ValueHandle
/// objects that watch it and listen to RAUW and Destroy events. See
/// llvm/IR/ValueHandle.h for details.
class Value {
Type *VTy;
Use *UseList;
const unsigned char SubclassID; // Subclass identifier (for isa/dyn_cast)
unsigned char HasValueHandle : 1; // Has a ValueHandle pointing to this?
unsigned short SubclassData;
...
}
通过value的注释,我们基本可以了解到:
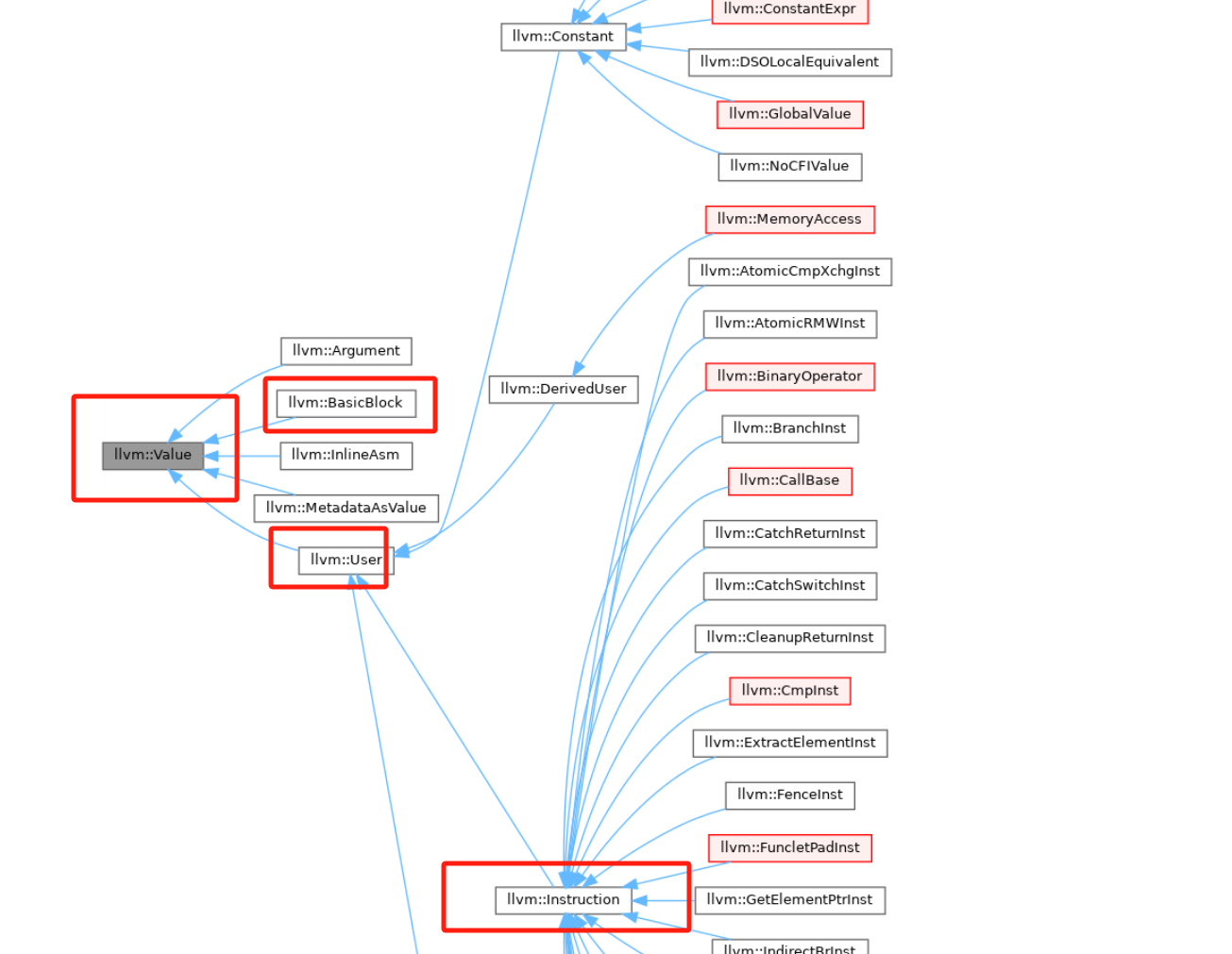
value是llvm中的基类。比如用到最多的Instruction、还有Function、BasicBllock等等都是value,下图展示了value的继承类。任何
Value都有一个类型。并且有名字的value会自动注册到module的符号表中通过添加一个
Use类的UseList指针,用于跟踪使用过该Value的其他值。后面会详细介绍Use类的用法另外一个重要的成员是SubclassID, 这是一个const值, 用来指示这个Value的子类型. 其用于isa<>与dyn_cast<>的判断.详细可以看网上关于llvm的RTTI介绍。
下面就是重点介绍User、Use类,大家通过上述的一些文章已经了解整体设计,或者有些懵懵懂懂的。
别着急,我下面梳理下具体细节和总结点
初识User、Use类
首先我们要理解llvm使用User、Use类的目的就是在生成Instruction的时候就建立好指令之间的User-Usee关系(还有BB间的关系)。有些编译器会先创建好ir后再通过遍历实现上述目的。这也是llvm设计的精巧之处,不然没有这么复杂o( ̄︶ ̄)o。当然要是SSA形式的ir,这样能保证每个value(def)的唯一性
带着这个目的,我们可以思考下:
一条Instruction的User和Usee是什么?如下图1
llvm如何生成一条指令的,并且建立好User-Usee关系?
如何通过User找到所有Usee,或反向通过Usee找到所有的Users?双向的,如下图2
为什么User是继承Value,而Use是包含Value的?
图1:

图2:

一条Instruction的内存布局
深入浅出 LLVM之 Value 、User 、Use 源码解析这篇文章的大佬在其中一章中对一条Instruction的创建和内存布局描述的很详细了,我这里就不再细说了。总结下:
Instruction的继承关系:
Instruciotn <-- User <-- Value。这其中User类的作用就是主导User(Value)和Uses的内存布局,也可以说建立好User(Value)->Usee链关系。一个Instruction创建一个User和几个Use(operand)是固定的一块内存。是通过
operation new和placement new自定义new的方式分配内存并初始化(之前介绍llvm读文件到内存的MemoryBuffer类也是通过这种方式实现)这样设计的好处是User在寻找Usee时可以直接通过计算Use*偏移就可以得到第几个操作数了。不用维护链表所以我们看到User里面很干净,连Use的指针都不需要保存,也节省了空间。
其中,有两种布局方式(如下图,这里的P就是Use):
a) 固定数量的Use:
User::allocateFixedOperandUser方法b) 大数量的Use:
User::allocHungoffUses方法
Layout a) is modelled by prepending the User object by the Use[] array.
...---.---.---.---.-------...
| P | P | P | P | User
'''---'---'---'---'-------'''
Layout b) is modelled by pointing at the Use[] array.
.-------.------...
| Use** | User
'-------'------'''
|
v
.---.---.---.---...
| P | P | P | P |
'---'---'---'---'''
https://www.llvm.org/docs/ProgrammersManual.html#the-core-llvm-class-hierarchy-reference
User类的作用:User–>Usee
如下是User的定义和部分重要函数
class User : public Value {
LLVM_ATTRIBUTE_ALWAYS_INLINE static void *
allocateFixedOperandUser(size_t, unsigned, unsigned);
protected:
/// Allocate a User with an operand pointer co-allocated.
///
/// This is used for subclasses which need to allocate a variable number
/// of operands, ie, 'hung off uses'.
void *operator new(size_t Size);
/// Allocate a User with the operands co-allocated.
///
/// This is used for subclasses which have a fixed number of operands.
void *operator new(size_t Size, unsigned Us);
/// Allocate a User with the operands co-allocated. If DescBytes is non-zero
/// then allocate an additional DescBytes bytes before the operands. These
/// bytes can be accessed by calling getDescriptor.
///
/// DescBytes needs to be divisible by sizeof(void *). The allocated
/// descriptor, if any, is aligned to sizeof(void *) bytes.
///
/// This is used for subclasses which have a fixed number of operands.
void *operator new(size_t Size, unsigned Us, unsigned DescBytes);
template <int Idx> Use &Op() {
return OpFrom<Idx>(this);
}
template <int Idx> const Use &Op() const {
return OpFrom<Idx>(this);
}
private:
const Use *getHungOffOperands() const {
return *(reinterpret_cast<const Use *const *>(this) - 1);
}
Use *&getHungOffOperands() { return *(reinterpret_cast<Use **>(this) - 1); }
const Use *getIntrusiveOperands() const {
return reinterpret_cast<const Use *>(this) - NumUserOperands;
}
public:
const Use *getOperandList() const {
return HasHungOffUses ? getHungOffOperands() : getIntrusiveOperands();
}
Value *getOperand(unsigned i) const {
assert(i < NumUserOperands && "getOperand() out of range!");
return getOperandList()[i];
}
Use &getOperandUse(unsigned i) {
assert(i < NumUserOperands && "getOperandUse() out of range!");
return getOperandList()[i];
}
unsigned getNumOperands() const { return NumUserOperands; }
// Methods for support type inquiry through isa, cast, and dyn_cast:
static bool classof(const Value *V) {
return isa<Instruction>(V) || isa<Constant>(V);
}
};
如何通过User找到Usee?
原理就很简单了。由于uses的内存是固定分配好的,通过Use的首地址后计算index的偏移量,如下函数实现:
getOperand函数Op<>()函数(通过模块偏特化实现的,可以静态检查index数量)
这里补充下像Op<-1>()的实现(负索引的话代表从后往前),是通过模板偏特化实现的。好处是可以静态检查index范围是否合法。但是需要每个Instruction子类都要实现偏特化。如下代码:
template <int Idx> Use &Op() {
return OpFrom<Idx>(this);
}
template <int Idx, typename U> static Use &OpFrom(const U *that) {
return Idx < 0
? OperandTraits<U>::op_end(const_cast<U*>(that))[Idx]
: OperandTraits<U>::op_begin(const_cast<U*>(that))[Idx];
}
template <class>
struct OperandTraits;
template <>
struct OperandTraits<BinaryOperator> :
public FixedNumOperandTraits<BinaryOperator, 2> {
};
template <typename SubClass, unsigned ARITY>
struct FixedNumOperandTraits {
static Use *op_begin(SubClass* U) {
static_assert(
!std::is_polymorphic<SubClass>::value,
"adding virtual methods to subclasses of User breaks use lists");
return reinterpret_cast<Use*>(U) - ARITY;
}
static Use *op_end(SubClass* U) {
return reinterpret_cast<Use*>(U);
}
static unsigned operands(const User*) {
return ARITY;
}
};
Use类的作用:Usee–>User
这里是我当时看到比较迷糊的地方,我详见介绍下
首先看下Use类的定义:
/// A Use represents the edge between a Value definition and its users.
///
/// This is notionally a two-dimensional linked list. It supports traversing
/// all of the uses for a particular value definition. It also supports jumping
/// directly to the used value when we arrive from the User's operands, and
/// jumping directly to the User when we arrive from the Value's uses.
class Use {
...
private:
Value *Val = nullptr;
Use *Next = nullptr;
Use **Prev = nullptr;
User *Parent = nullptr;
void addToList(Use **List) {
Next = *List;
if (Next)
Next->Prev = &Next;
Prev = List;
*Prev = this;
}
void removeFromList() {
*Prev = Next;
if (Next)
Next->Prev = Prev;
}
};
通过上面Use类的注释,我们知道,Use类的作用有两点:
通过User可以找到所有的operands:User->Usee(我们在上一节介绍了实现)
通过Value’s uses可以找到使用他的那些User:Usee->User(在这一节详细介绍下其实现)
虽然注释里说Use类似是一个edge作用,但是我这里把Use看成一个槽的概念更好理解。结合上面Use的内存布局图(所以use和value是包含关系)。一个User(Instruction)创建出的几个Use(operands)是固定的一块内存。所以说我们在创建User的时,他的几个Use槽就固定好了,里面具体填什么value可以随时替换。
但是Use的next和prev组成的双向链表是干嘛的呢?
其实在填value的时候,同时会调用addToList(Use **List)函数将这个use插入到value里的useList(头插法)中。这样,通过遍历useList就可以找到这个value所有的user了。
A: %add = add nsw i32 %a, %b
B: %add1 = add nsw i32 %a, %b
上面这个例子,%a是一个value,他的uselist链表维护两个user,如下
NULL
↑
.----.----.-----------.
| %a | %b | %add:User |
'----'----'-----------'
use1↑ use2
↑
.----.----.------------.
| %a | %b | %add1:User |
'----'----'------------'
use3↑ use4
↑
%a:value:uselist*
具体怎么实现的,仔细看下面的代码,有点绕。
理解addToList removeFromList操作(重要)
void Use::addToList(Use **List) {
Next = *List;
if (Next)
Next->Prev = &Next;
Prev = List;
*Prev = this;
}
void Use::removeFromList() {
*Prev = Next;
if (Next)
Next->Prev = Prev;
}
Prev和addToList参数为啥用双重指针?
双重指针prev除了prev*代表前驱。prev还可以作为head*:因为是头插法,通过Prev = List;*Prev = this;第一个Prev指向的其实就是UseList*(后面通过Next->Prev = &Next更新prev*)。避免需要caller去维护head*。所以value里UseList*在use插入后会自动更新最新的head
解释如下: https://stackoverflow.com/questions/7271647/what-is-the-reason-for-using-a-double-pointer-when-adding-a-node-in-a-linked-lis
借用下大佬的图帮助理解:
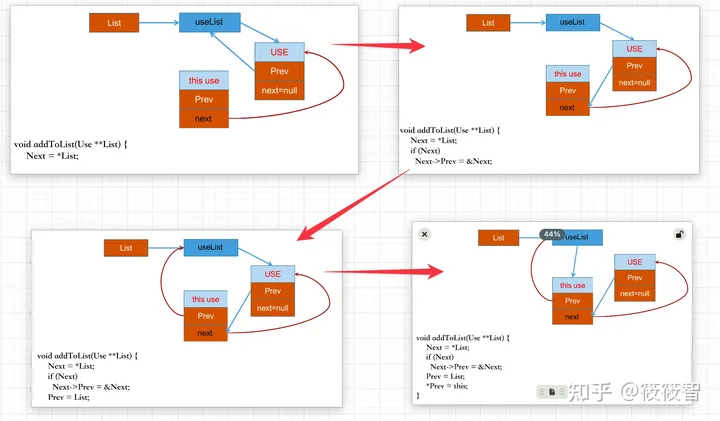
同理,删除操作就比较简单了
单个use的插入/删除
void Use::set(Value *V) {
if (Val) removeFromList(); // 如果Use槽里已有value,在旧Value的UseList列表中删除这个Use的链接
Val = V; // Use槽里设置新value
if (V) V->addUse(*this); // 并同时将这个Use插入到新value的UseList列表中
}
/// This method should only be used by the Use class.
void Value::addUse(Use &U) { U.addToList(&UseList); }
Value *Use::operator=(Value *RHS) {
set(RHS);
return RHS;
}
const Use &Use::operator=(const Use &RHS) {
set(RHS.Val);
return *this;
}
再回头看看Use::set的操作就很好整体理解了
如果Use槽里已有value,在旧Value的UseList列表中删除这个Use的链接
Use槽里设置新的value, 并同时将这个Use插入到新value的UseList列表中
整体替换/删除Value对象
我们上面展示的例子中,如果要更新%a这个usee的value,需要将use1和use3槽都更新了。
llvm提供了统一更新的接口:被称为RAUW(replace all uses with)的操作(这类技巧在LLVM代码框架中随处可见), 其接口被replaceAllUsesWith方法封面。定义见Value类。
void Value::replaceAllUsesWith(Value *New) {
doRAUW(New, ReplaceMetadataUses::Yes);
}
void Value::replaceNonMetadataUsesWith(Value *New) {
doRAUW(New, ReplaceMetadataUses::No);
}
void Value::doRAUW(Value *New, ReplaceMetadataUses ReplaceMetaUses) {
assert(New && "Value::replaceAllUsesWith(<null>) is invalid!");
assert(!contains(New, this) &&
"this->replaceAllUsesWith(expr(this)) is NOT valid!");
assert(New->getType() == getType() &&
"replaceAllUses of value with new value of different type!");
// Notify all ValueHandles (if present) that this value is going away.
if (HasValueHandle)
ValueHandleBase::ValueIsRAUWd(this, New);
if (ReplaceMetaUses == ReplaceMetadataUses::Yes && isUsedByMetadata())
ValueAsMetadata::handleRAUW(this, New);
while (!materialized_use_empty()) {
Use &U = *UseList;
// Must handle Constants specially, we cannot call replaceUsesOfWith on a
// constant because they are uniqued.
if (auto *C = dyn_cast<Constant>(U.getUser())) {
if (!isa<GlobalValue>(C)) {
C->handleOperandChange(this, New);
continue;
}
}
U.set(New);
}
if (BasicBlock *BB = dyn_cast<BasicBlock>(this))
BB->replaceSuccessorsPhiUsesWith(cast<BasicBlock>(New));
}
bool materialized_use_empty() const {
return UseList == nullptr;
}
重点在这个while循环和其中的U.set(New);。
初看循环中没有直接的UseList指针偏移,会很奇怪循环什么时候跳出?
其实,结合上一节已经我们对Use::set方法的介绍,双重指针会维护UseList的更新。旧值value的UseList链表其实在依次被删除,直到为空。
关于上面ValueHandle的解释:详见LLVM笔记(16) - IR基础详解(一) underlying class
引用
http://www.cs.toronto.edu/~pekhimenko/courses/cscd70-w18/docs/Tutorial%202%20-%20Intro%20to%20LLVM%20(Cont).pdf